The basic issue tracking system
The issue tracking system per se consists of a single list of issues. Since there is only one customer, there's no need to track customers. Since there are only two really meaningful subsystems, I see no need to muddy the waters by tracking them, either. So this is an example of what I've been thinking of as a "simple bug-tracking system," and it's a good place to start working on a real live system.I call the single issues list "issues", and I end up with a site description file like this:
<site> <list id="issues" defn="issues.xml" order="priority desc, date"/> </site> |
<list> <field id="id" special="key"/> <field id="date" type="date" special="add"/> <field id="expected" type="date"/> <field id="desc"/> <field id="notes" type="wiki" rows="10" cols="80"/>> </list> |
I also create a directory named "issues" in my main directory; this will store each issue file, which will be a localdir XML file by default. Note that I could have chosen a different storage area for the issues list.
The "order" attribute on the list definition defines the default order for issue listings. This could be omitted entirely to save some overhead, but it makes a lot of sense to use it, especially once we get into publishing below.
The notes field is a "Wiki text"; it is edited as a textarea (with the rows and columns as specified in its field definition) but formatted as structured text. My inspiration for this was the WikiWikiWeb concept which you can easily find in Google; the point is to make it simple to produce formatted text, links and all, without typing HTML. In my structured text setup, skipped lines are paragraph breaks, asterisks introduce links, and so forth. True to wftk form, I haven't yet documented this (partly because I expect it to remain in flux for a while.) The point is that the notes are designed to be quick ways to create formatted content.
So far, time expended (ignoring the time I'm taking to document this) has been under ten minutes. If I had a fully functional front-end, I'd really already have a simple issue tracking system, because the wftk already supports tasks against objects (like issues), indexing of tasks, and so forth. But I don't have a front-end yet, just pieces of them. Let's talk about the front end a little.
I kind of like this model for active site development. Information that doesn't
change often can be written a single time and then handed out to many viewers with only minor processor
overload. This would, therefore, scale very well. But it still permits the normal navigation of the
data to be used to find items to modify and actions to take, so that (active) users of the site needn't
keep two pictures of the data in their heads at once.
A second advantage of static HTML (or other static data representations, like an XML file of some sort)
is that it lends itself to publishing on some system other than the one actively hosting the bug
tracker. In the Techspex case, this doesn't apply, but it can be seen as a distinct advantage.
At any rate, the front end for this system breaks conveniently into two portions: static HTML publishers
for system and issue status pages, plus active maintenance code to make actual changes to the issue
list. The first is well-supported by code current in December 2002, while the latter category is only
spottily supported -- at the moment, it is partially addressed by the CGI front end, but that's the
extent. So as part of this exercise, I'm going to address myself first to fixing up the CGI front end
sufficiently to work for this system, but I'd also like to start laying out a native AOLserver front end,
since that's the HTTP server used by Techspex and thus I'd like to use it in other Techspex applications.
Note that the page value for the page "issue" contains square brackets like this:
The "displays" attribute on the issues page is there to tell the CGI data management interface that when
displaying the full list after modification, it should use that page. This allows the published page to
be an effective center for navigation when editing the list.
So now all we have to do is define three templates: the overall site layout, the issue list template, and the
issue detail template. Since this system isn't really for public consumption, there's very little
reason to pretty it up, so I'm going to keep all of this to a bare minimum to make it easier to see
what's where (and also to save me some development time.)
All layouts are effectively templates, that is, they are XML which is run through the
xml_template library and then written using xml_writehtml, which makes sure, for instance, that the XML
element
Here's the general layout:
We have two different basic kinds of page here; one lists entries from a list as a table, while the
other publishes an individual object. A list template must contain a
The list template is the longest file I've quoted yet, but it's still pretty easy to understand:
Order in list retrieval is specified using an SQL-standard order specifier. If the underlying storage
is an RDBMS, then this spec is used directly when building the query; otherwise, it's passed to the
xmlobj_list_sort function by non-RDBMS adaptors.
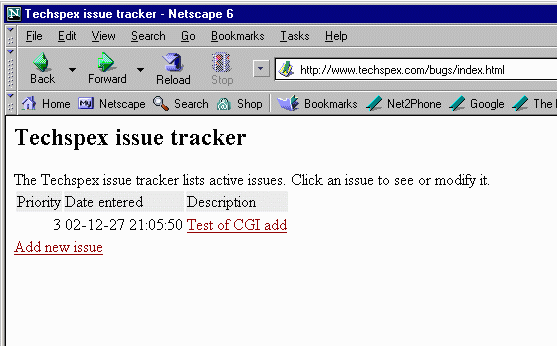
When we insert a single test task into the list with the above index template, the result looks like this:
For the detail, we build a similar very simple template as follows:
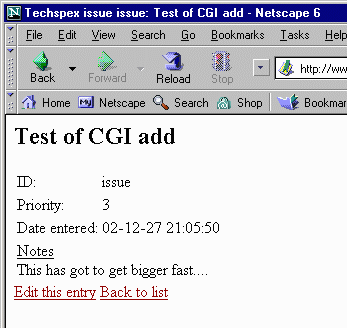
The test task referenced above ends up looking like this:
This much gives us a basis for working with the system, even if there is as yet no mature Web interface to
manage data; to date, when using the publishing code of the repository manager, I either enter the
data by hand through the repmgr command-line interface plus a text editor invoked by the CLI, or I
generate the data using Perl scripts running on the system, and simply use the repmgr "publish" command
to run off a set of pages showing the current state of the system. I can use either of those
approaches with this system as well. But naturally, a Web interface for data management will make
the system far, far easier to use.
The issue detail above links to repmgr.cgi
to "Edit this entry" -- that and the analogous "Add issue" link on the index page are our means of
entry to the data management interface. Beyond making sure that a CGI symlink is present in the repository
directory, there's nothing more to specify in order to provide CGI access to the system. Once alternative
front ends are available, they will likewise be precisely this easy to set up, since they all work off
the same site definition file we use for publishing information. At most we need to set configuration
parameters (like the "displays" attribute on the index page) in order to modify the default way in which
a front end works.
The best way to handle this is to build a state machine for the issues list. If we have two states (say, "active"
and "resolved") then we can specify archival when the issue reaches the "resolved" state. Archival moves the object
into a second list, where it can be published using completely different templates, if necessary. This is rather
handy, since the template for a resolved issue can be made visibly different, making it easy to see that something
has changed.
The list template for resolved issues can also publish to a separate page, and can sort by something other than
priority -- say, by resolution date. And if we specify the archival list with an "add" date, it will automatically
mark the date of resolution of the issue.
Another benefit the state machine gives us is that we can define more states -- for instance, we could define an
"emergency" state for an issue. The emergency state could be triggered by an automatic process which scans
active issues for signs of neglect, and entry of the emergency state could notify management, or page a senior
developer, or ... whatever. The "whatever" is the whole point of a workflow toolkit, after all.
To set all this up, we add a new list "issue_archive", and define the state machine for the issues list. Both of these
are done in site.opm (although the state machine could just as well be defined in the defn file for the issues list,
issues.xml -- the definition is merged with the information already in site.opm, so it doesn't really matter where
we define the state machine.) The resulting site.opm, which is getting a little more ungainly as a simple example,
looks like this:
The "archive-to" attribute on the resolved state indicates that this state is a sink -- that is, when
the object hits this state, it will be moved entirely into the issue_archive list. An archival state
circumvents any workflow attached to an object, and archival removes all active workflow (or at least,
these statements will be true once the integration of the repository manager with the wftk core is
complete.) However, the addition to the new list can invoke whatever workflow is required in the
context of the new list. From a state-machine point of view, an archival transition can be seen as a
compartmentalization of the state machine into manageable submachines (one per list.)
The issue archive has no state machine, and thus cannot transition back to the issues list. There's a case to be made
either for the ability to bring an issue back to life by making it an active issue, or forcing the system to create a
new issue instead -- I've opted for the latter, mostly because it's simpler. It could easily be changed, of course,
by defining an "archiving" state machine for issue_archive.
Front end planning
Presentation of issues can be seen in terms of use cases, more or less as follows:
Of these, the status pages can easily be thought of as either live database queries or as published
static HTML pages. Since I haven't involved a database with this system yet, that leaves me with
published static HTML pages. I'll want to create two publishers which will be called whenever the
list of issues is changed. The first will be a list template to publish a sorted list of all active
issues; the second will operate for each issue and will publish a static representation of that issue.
The static issue page will also include hooks for actions to be taken.
Publishing static HTML for system status
Let's go ahead and define our publishers for the issue list. This is really pretty easy; first we define
two pages to provide a place for the publishers to publish to, and then we provide the publishers.
We modify the site.opm file to look like this:
<site>
<list id="issues" defn="issues.xml"/>
<page id="issues" page="index.html" displays="issues"/>
<page id="issue" page="issue[id].html"/>
<publish id="issues" from="issues" to="issues" defn="index_template.xml"/>
<publish id="issue" from="issues" to="issue" defn="issue_template.xml"/>
<layout id="default" defn="layout.xml"/>
</site>
issue[id].html.
This is something I call a flat template (because it's not an XML template like the ones we're about
to define below) and it gives us a simple way to specify how to build a filename for the static HTML
file associated with any particular object: we simply replace [id] with the value of the
"id" field for the object. Nifty.
<br/> gets turned into <br> and the like. Slots in the
templates are filled using template:value elements. For the general layout, there is one slot named
"content" defined by the system; that will be the default target of whatever page is published. A
layout may also optionally define other value slots, which can be filled in using a couple of different
mechanisms, only one of which I'll be using here, to fill in the title slot.
<layout type="page">
<head>
<title><template:value name="title"/></title>
</head>
<body bgcolor="#FFFFFF" link="#000099" vlink="#990000" alink="990000">
<template:value name="pagetitle"/>
<template:value name="content"/>
</body>
</layout>
template:list
element, which will connect with the list in question, retrieve it, order it, and proceed.
<list>
<template replaces="title">Techspex issue tracker</template>
<template replaces="pagetitle"><h2>Techspex issue tracker</h2></template>
<template>
The Techspex issue tracker lists active issues. Click an issue to see or
modify it.
<table>
<tr>
<td bgcolor="eeeeee">Priority</td>
<td bgcolor="eeeeee">Date entered</td>
<td bgcolor="eeeeee">Description</td>
</tr>
<template:list order="priority desc, date">
<tr>
<td align="right"><template:value name="priority"/></td>
<td><template:value name="date" format="date"/></td>
<td><template:value name="desc" format="link:issue[id].html"/></td>
</tr>
</template:list>
</table>
<template:value format="link:repmgr_cgi?mode=new&list=issues">Add new issue</template:value>
</template>
</list>
<list>
<template replaces="title">Techspex issue <template:value name="id"/>: <template:value name="desc"/></template>
<template replaces="pagetitle"><h2><template:value name="desc"/></h2></template>
<template>
<table>
<tr><td>ID:</td><td><template:value name="id"/></td></tr>
<tr><td>Priority:</td><td><template:value name="priority"/></td></tr>
<tr><td>Date entered:</td><td><template:value name="date" format="date"/></td></tr>
<tr><td colspan="2"><u>Notes</u><br/><template:value name="notes"/></td></tr>
</table>
<template:value format="link:repmgr_cgi?mode=edit&list=issues&key=[id]">Edit this entry</template:value>
<a href="index.html">Back to list</a>
</template>
</list>
Data management interface (adding/modifying issues)
Even though my heart wants to build a native AOLserver interface for this system, my head is telling
me there's no chance I'll get around to that in a timely fashion. So instead I'm going to recycle the
repmgr CGI interface, which is already half-done as of this writing (December 2002). I'm hoping that
using this system on a more or less daily basis will motivate me to make improvements to the CGI
interface (most of which will probably be easily wrapped in Tcl to create an AOLserver-native version.)
Resolving issues and archiving resolved issues
At first glance, resolving issues is simple -- we just delete the issue. However, this really isn't a great way
to handle resolution, for two reasons (neither of which is that the CGI interface doesn't delete things yet as
of this writing).
First, when a list entry is deleted, the publisher doesn't remove the file
it was published to. If someone has bookmarked the page, a fresh visit won't tell them that the issue has been
resolved; it will simply have vanished from the master list of open issues, leaving a fossil detail page in place.
Moreover, deletion doesn't provide
any history at all -- when was the issue resolved? How long did the resolution take?All in all, maintaining a
database of only active issues is a weak solution.
<site>
<list id="issues" defn="issues.xml" order="priority desc, date">
<state id="active" label="Active"/>p
<state id="urgent" label="Urgent"/>
<state id="resolved" label="Resolved" archive-to="issue_archive"/>
</list>
<page id="issues" page="index.html" displays="issues"/>
<page id="issue" page="issue[id].html"/>
<publish id="issues" from="issues" to="issues" defn="index_template.xml"/>
<publish id="issue" from="issues" to="issue" defn="issue_template.xml"/>
<list id="issue_archive" defn="issue_archive.xml" order="resolved desc"/>
<page id="issue_archive_list" page="old_issues.html"/>
<page id="issue_archive_detail" page="issue[id].html"/>
<publish id="issue_archive_list" from="issue_archive" to="issue_archive_list" defn="archive_template.xml"/>
<publish id="issue_archive_detail" from="issue_archive" to="issue_archive_detail" defn="archive_detail_template.xml"/>
<layout id="default" defn="layout.xml"/>
</site>
Interaction with CVS
Since I manage the code for Techspex.com using CVS, I'd like some integration between CVS and the
issue tracking system. The real question is what form this integration should take; I have a number of interesting
possibilities, none of which are actually working yet.
Anyway, eventually I'll get around to exploring all this. Watch this space for further details.
This would effectively mean that wftk would access the CVS logging functions and store informative information
about events in CVS, and it's a reporting feature. This would link "cvs diff" to active issues, which would
involve some extra accounting overhead while programming. The obvious way to deal with this would be for a
cron job to check "cvs update" periodically and make sure there are no changes which weren't accounted for;
if new changes were detected, then they'd go into a task list of "stuff to resolve". This would augment the
list of current issues with a shorter list of "active issues" -- issues attached to currently changed files
which haven't been committed yet.
\
Since I run two versions
of the Techspex site (one with a sandbox set of code for pretesting changes, and the actual production site),
code gets checked in and moved into production after an issue is resolved. This would utilize the code-change-to-issue
link from above.
This works in the other direction, of course -- if I commit a code change or set of changes, then it would be
equivalent to the resolution of the issue. This could be done in either of two ways. If we want to build a
Web interface to the resolution/commit system, then that system would do whatever's necessary. But sometimes
it's convenient to use CVS from the command line, and in this case it would be dangerous to allow commit without
some way to close out active issues for consistency's sake. So it would be nice if we could use CVS's commitinfo
or loginfo hooks to take appropriate action when a code file is committed. (It would be even nicer if we could
initiate workflow on such a commit, and officially commit the file only upon approval, but that will require some
more finicky work than what I'm talking about here.)
Where from here?
There are naturally an infinite number of features which one can incorporate into any system, and the bug tracker (even the
simple one!) is no exception. I haven't had much time to write anything down, but eventually there will be more.
Copyright (c) 2002 Vivtek. Please see the licensing
terms for more information.