Topic: wftk -- Server design overview[ wftk home ] [ discussion ] |
In working through the various usage scenarios I came up with a list of overall design
goals, and what I consider a pretty solid server design. Here are the overall goals I see for this project:
As Anthony says, "It has to be easy enough for even a vice-president to use." This not only applies to the actual running of processes, but it must be simple for an untrained person to design a workflow process. This is our paramount goal: we need a system which can be used by the small organization with no specialized technical staff. Getting processes designed can't wait for an IT staff to get around to it; it should be as easy to learn as a word processor. (After all, twenty years ago the formatting of a document was also something usually left to experts. Now my five-year-old does it for fun.) To be easy to use, the system must also be easy to install. At least for selected system configurations, installation should be as simple as a typical Windows program: put in the disk, answer some questions, and start using the system. I consider this part of the ease-of-use criterion, but it bears explicit statement. Specifically, ease of deployment and support means that the code must be extremely stable. I should be able to install it once and let it run for a year or two and never need to worry about it. This can be attained by keeping the code small, simple, and modular. I think. Ask me again this time next year. By this I mean that if the local environment already contains a database system, the workflow toolkit should be able to take advantage of the existing database. This would be achieved by means of adapters, modules written for the specific system in question which present a unified API to the workflow engine. I'd like to see adapters in use for the following components, at least: the database system, the Web server, the document management facility (both the repository for process definitions and for deliverable storage, which may well be separate repositories), directory services for users and groups, and messaging services. Some similar approach may be useful for interpreting process definitions created by other systems. This is sort of an ideal goal, as ad-hoc workflow is in large part a research topic still. But I think that our advantage of starting fresh in 2000 will allow us to address some of the weaknesses of existing technology. Ad-hoc workflow, instead of focussing on the control of business processes, simply tries to document actual business actions. Since each business action taken outside the planned workflow weakens the workflow system, I'd like to incorporate an ad-hoc action tracking capability into the system. The workflow industry is kinda sorta trying to standardize. They're not getting very far at it, but there are some standards which are actually emerging, chiefly those of the WfMC (the Workflow Management Consortium, a group of workflow vendors and corporate users). The WfMC has defined five interfaces to a workflow engine: the process definition interface, the interface to the database, the interface to the user and to invoked applications, and an interface to allow communication between workflow engines, allowing a single process to be distributed across platforms Ideally the wftk would be able to work with all these interfaces. (A reader suggested the SWAP group as another standards body, but everybody I've talked to says SWAP is dead. Their ideas were pulled into the WfMC interfaces to a certain extent.) (Thanks to Thomas Fricke for bringing this up as a design goal.) Multiple workflow engines should be able to work cooperatively to distribute load over multiple machines. It might also be a good idea to allow distribution of each individual repository component over multiple machines, but I'm less clear on how that would be implemented.
System overview 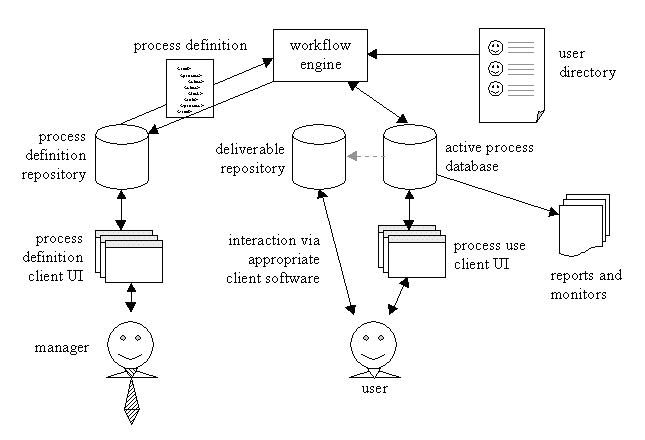 Let's talk about these pieces, starting with the manager in the lower left-hand corner and going up and around and down to the user in the lower right-hand corner. If a heading has an asterisk next to it, that means that I plan to make that part an adapter (so that it is effectively plug-compatible.) Once you've scanned this list, if you haven't already, go read the usage scenarios, because they highlight how the various components actually get the job done.
Manager
Process definition client UI * The screens proposed in the original RFP are pretty straightforward for this.
Process definition repository * I can imagine a set of rules that a designer could specify as to how active processes should switch midstream, but that's definitely out of the scope of the present project. Note that the engine also has an arrow pointing back to the repository. I envision ad-hoc process documentation and exception handling as being the creation of alternate versions of a process. So in the event that a process doesn't actually follow its original definition, the engine should ideally update a special version of the definition back in the repository. (1/27/00) As Thomas Fricke has noted, the goal of scalability would be well served by allowing multiple repositories to cooperate in the system. I think the best way to implement this is to allow initiation of processes to specify the location of the process (that is, to specify the repository in which the process is located.) Then the active process would reference that repository+definition+version. In fact, since the process definitions are XML, it would be most reasonable to allow retrieval over the Internet via HTTP request. In this case, it would be best to cache the version retrieved in a local process definition repository, so that sudden unavailability of the remote repository wouldn't cause the process to come to a screeching halt. And then ad-hoc changes to the active process would be noted in the local repository as well. Updates and feedback could be done via an HTTP POST -- to that end, a process definition should include a URL embedded within it which should be used for automated feedback. Note that this potentially allows the free distribution of useful workflow patterns over the Internet... That could be, well, darned interesting!
Process definition
Workflow engine (1/27/00) Note that consonant with the goal of scalability, this component should actually be considered an arbitrary group of individual workflow engines. This isn't too hard to imagine: each time a task is registered as completed (or rejected, or whatever), then instead of a single machine having to handle that update, one of a number of engines is selected based on whatever queueing criteria is deemed necessary (probably load balancing or performance monitoring criteria). The engine selected then retrieves the process definition and performs the necessary updates. One danger I see in this is that two engines could conceivably be updating a process at the same time. This isn't a problem as long as neither needs to do exception handling (thereby modifying the process definition, remember?) However, in the case that the process definition is to be modified, there will have to be some sort of coordination between the engines.
Directory *
Deliverable repository *
Active process repository * At any rate, the active process repository retains information about active processes. I was going to draw a schema but once I started it I realized that it reduced to two boxes, so I just wrote more detailed information about the database structure; click here to see it. If the values for a process are stored as an XML document, those could either be stored in a BLOB in the RDBMS, or as a standalone document in the deliverable repository. Either solution would work out fine. Note there's a grey dotted arrow from the active process repository to the deliverable repository. This represents the link between completed tasks and the deliverables which the user has associated with them.
Process use client UI * Again, no surprises on the screens requested here:
Reports and monitors * A couple have already been proposed, but of course reporting is one thing we'll learn about as we get into prototyping:
|

This work is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License.